In his iconic short story “The Library of Babel” (1941), Jorge Luis Borges describes a fantastical library that contains every book that could ever be written. Yet, despite such a wealth of information, most books are effectively useless, driving the librarians to madness in search of orientation. Today, anyone learning a new language online or sifting through the deluge of educational tutorials may experience a similar plight. Most learning apps do not adapt effectively to individual abilities the way a teacher would, leading to endless repetition of nonsensical phrases, for example. When learning from videos or blog posts, it is often impossible to link all this knowledge together into a coherent curriculum. Yet, what if artificial intelligence (AI) were able to act as a librarian and teacher, helping to empower learners by adaptively guiding them to the most useful content?
In our recent work, presented as a spotlight at ICLR, we address these challenges with a new machine learning approach to the problem of “structured knowledge tracing”. Our system tracks student knowledge in real time, allowing us to predict with high accuracy how well they will perform on any new assignment. Down the road, this will help us to recommend which concepts a learner should engage with next. Our model is called “PSI-KT,” standing for Predictive, Scalable, and Interpretable Knowledge Tracing, with these three elements providing the key foundations for future tutoring systems. So, how does PSI-KT work?
Predicting learning through knowledge tracing
To help students reach their learning goals, a tutor needs to suggest appropriate learning activities. This requires the tutor to have a good picture of what a learner knows at any time — a task known as knowledge tracing.
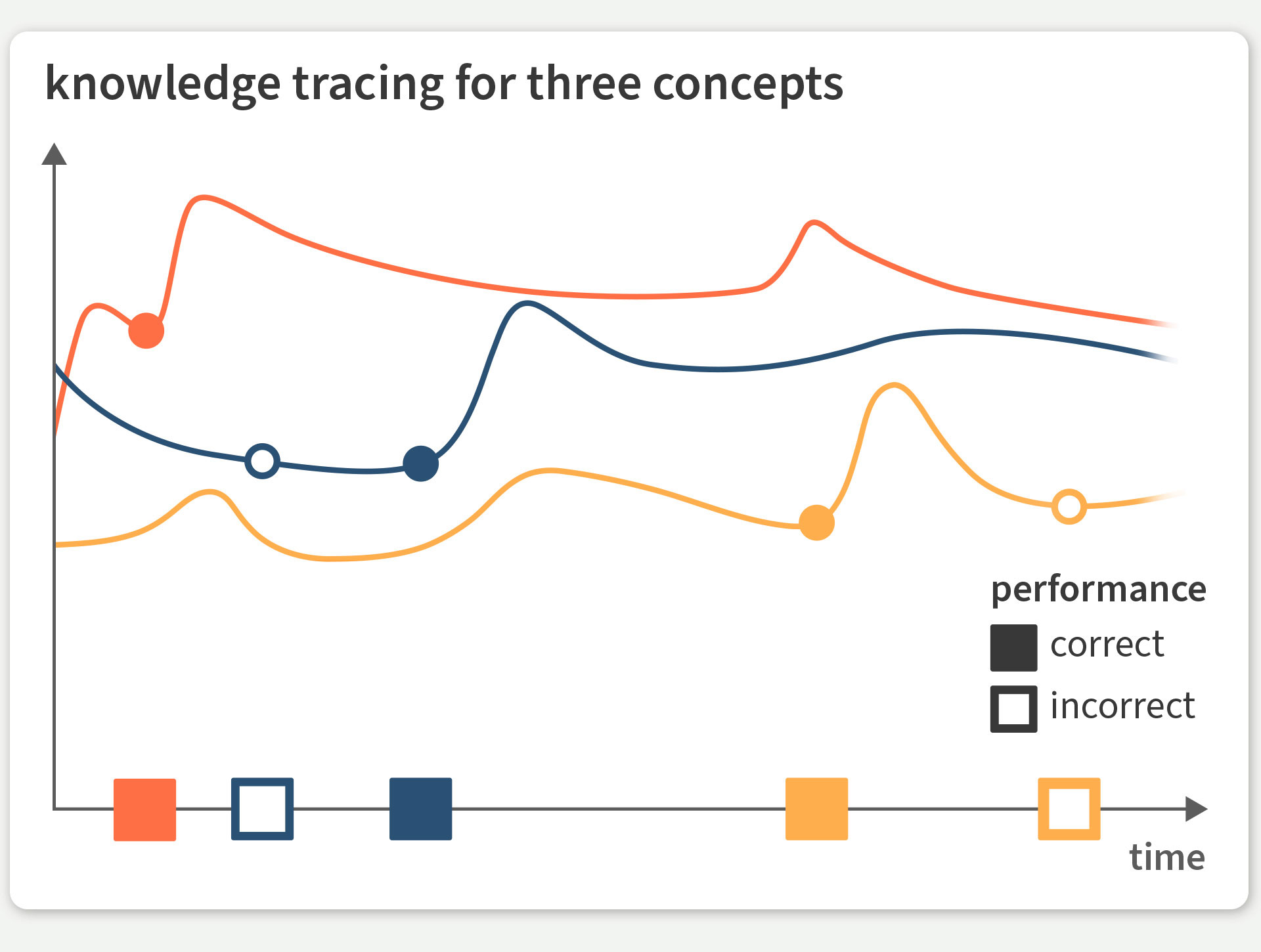
Fig. 1: Based on the successes (filled squares) and failures (empty squares) observed as a learner reviews different concepts (distinct colors), a knowledge tracing system estimates how the learner’s knowledge evolves over time and predicts future performance.
Mapping the structure of knowledge
One key aspect of our model is that it accounts for the prerequisite structure of knowledge. Educational psychologists speak of a zone of proximal development, consisting of knowledge and skills within reach, but requiring help. While a human tutor can easily give you the right nudge, online learning programs often lack the understanding of how concepts are related to one another. Thus, if we want accurate and useful knowledge tracing, we need to also find out which other notions support learning each concept. For example, learning to add two numbers together is a useful prerequisite for understanding multiplication. This is something we all learned in elementary school. Yet, how can we design an AI algorithm to be able to capture such prerequisite relations across any arbitrary domain of knowledge in the real world?
In PSI-KT, we rely on performance data: if, as expected, learners who practise addition prior to multiplication learn faster than those who do the reverse, then we deem addition a prerequisite for multiplication. An advantage of relying on order only is that establishing prerequisites does not depend on the names or contents of the assignments, which are rarely available in published datasets. More generally, it allows us to preserve privacy.
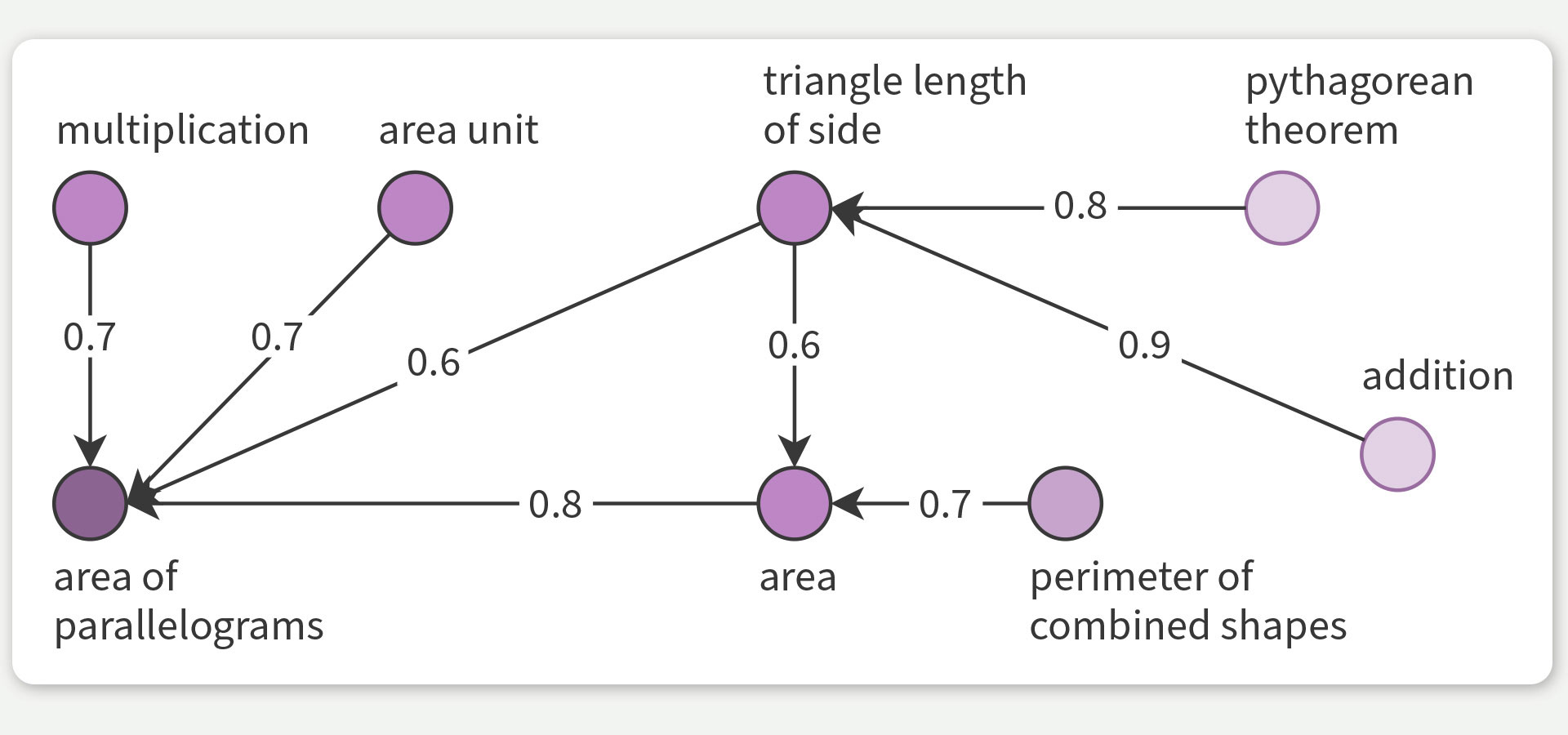
Fig. 2: Knowledge mapping estimates how much learning a concept facilitates learning others. PSI-KT’s estimates of prerequisite strength for the concept “area of parallelograms” (bottom left) appear as numbers between 0 and 1 on the arrows. PSI-KT uses performance data only, we show the concept labels just for illustration.
As we observe more performance data from all learners over time, our knowledge map improves to the point that it becomes useful to help predict their performance with future tasks and even for new learners who have not yet interacted with the system. This approach makes PSI-KT widely applicable across any domain, regardless of whether an expert-drawn knowledge map is already available.
Scaling up by adapting to new data
Another key challenge of using AI systems in education is that, while powerful, typical deep learning systems require massive amounts of data for training. This is further complicated by the need to update the model as new data comes in, which can be costly for both wallets and the environment.
Yet, unlike most machine learning models, PSI-KT can update its parameters without retraining from scratch. It is also able to learn general trends that are common across the entire population of learners. This allows us to make good guesses for a brand-new learner, even before they have contributed any interaction data for our model to learn from.
Interpretable personalization
Lastly, one unique advantage of our model is interpretability. Deep learning is often criticized for trading off predictive performance against interpretability. To make their predictions, other deep learning models of knowledge tracing typically represent each learner by a long list of numbers, each without any clear meaning.
PSI-KT, by contrast, was designed from the ground up to capture psychologically interpretable traits, such as how quickly a learner forgets, or how well they can make use of their existing knowledge of prerequisites. Using data from real educational platforms we show that this small number of traits consistently predicts observed learning patterns. This opens the door to providing actionable feedback about the learning process to the learner or to a teacher.
Conclusion
In conclusion, PSI-KT provides the foundation for a new generation of AI-powered tutoring systems, combining the science of human learning with machine learning. We hope that such future systems will provide learners with the guidance they need to avoid getting lost in the many possible paths of online learning.
Original publication: Zhou, H., Bamler, R., Wu, C. M., & Tejero-Cantero, A. (2024). Predictive, scalable and interpretable knowledge tracing on structured domains. The Twelfth International Conference on Learning Representations. https://doi.org/10.48550/arXiv.2403.13179
Cover illustration: Franz-Georg Stämmele

Navigating 20 Million Papers at Once to Uncover Knowledge

Comments