
Trotz vieler Fortschritte bei Deep-Learning-Algorithmen stellt die fehlende Nachvollziehbarkeit ihrer Entscheidungen ein großes Hindernis für deren Einsatz dar. Dies ist vor allem in sicherheitskritischen Anwendungsbereichen wie dem Gesundheitswesen relevant. Ein Grund für den Blackbox-Charakter ist, dass wir dem Modell mittels Trainingsbildern, die von Menschen klassifiziert wurden, zwar mitteilen, was es vorhersagen soll, aber nicht wie es zu dieser Entscheidung kommt. Diesen Vorgang führt der Algorithmus selbständig durch. Bei komplexen Modellen, die mit großen Datensätzen trainiert werden, ist daher oft nicht klar, auf welcher Grundlage sie bestimmte Vorhersagen treffen. So kommt es vor, dass Bildklassifikatoren Störsignale in den Daten aufgreifen, die sie daran hindern, das eigentlich gewünschte Konzept zu erlernen.
Wenn wir zum Beispiel ein Modell darauf trainieren, verschiedene Tierrassen wie Hunde, Katzen und Kühe voneinander zu unterscheiden, sollte das Modell ähnliche Merkmale auswählen wie auch ein Mensch, d. h. ein Katzenbild sollte als Katze eingestuft werden, weil es typische Merkmale, wie Katzenohren oder Fellmuster, aufweist. Wenn unser Datensatz jedoch bestimmte Verzerrungen enthält, kann sich dies im Klassifikator wiederfinden: Wenn beispielsweise die meisten Hundebilder in einem Wald aufgenommen wurden, die meisten Katzenbilder jedoch im Innenbereich, kann es passieren, dass das angelernte Trainingsverfahren ein Bild von einem Hund im Innenbereich als Katze einstuft. Dies ist darauf zurückzuführen, dass das trainierte Modell gelernt hat, dass der Hintergrund ein stärkerer oder einfacherer Indikator für die Tierrasse ist als das eigentliche Tier.
Bestehende Methoden zur Erklärung von Bilderkennungsmodellen beruhen häufig auf Auffälligkeitskarten, d. h. sie heben denjenigen Teil des Bildes hervor, der den größten Einfluss auf die Vorhersage hatte. Diese Karten geben jedoch keine Antwort darauf, warum dieser Teil des Bildes zur jeweiligen Vorhersage geführt hat. Zu diesem Zweck haben wir Algorithmen zur Erstellung sogenannter Visueller Kontrafaktischer Erklärungen (VKEs) entwickelt. VKEs sind bildspezifische Erklärungen eines Klassifikators, die einer menschlichen Argumentation nahekommen: „Ich würde dieses Pferdbild als Zebra wahrnehmen, wenn das Fell schwarze und weiße Streifen hätte.“ Formal betrachtet wendet man diese Methoden auf einen Klassifikator an und löst damit folgendes Problem: „Wie muss das Bild aussehen, damit es von unserem Modell als Zebra erkannt wird, wenn man ihm eine Zielklasse c vorgibt, wie z. B. Zebra im vorherigen Beispiel, während es gleichzeitig dem ursprünglichen Pferdebild ähnelt?“
Visuelle Kontrafaktische Erklärungen durch Diffusion (VKEDs)
In unserer kürzlich veröffentlichten Arbeit haben wir einen neuen Algorithmus vorgestellt, der so genannte Diffusionsmodelle verwendet, um solche VKEs (VKEDs) zu erzeugen. Diese Modelle sind darauf trainiert, neue Bilder zu erzeugen, die den Trainingsbildern ähnlich sehen, aber nicht mit diesen identisch sind.

Abbildung 1. Unsere Methode VKED erzeugt visuelle Kontrafaktische Erklärungen (VKEs), die die Entscheidungen eines beliebigen Klassifikators erklären kann. Dabei wir das Bild einer Klasse in das einer ähnlichen Zielklasse geändert, indem klassenrelevante Merkmale verändert werden, während die Gesamtstruktur des Bildes erhalten bleibt. Auf der linken Seite ändern wir die Vorhersage „Schimpanse“ in zwei andere Affenrassen um. In ähnlicher Weise ändern wir rechts die Vorhersage einer bestimmten Retriever-Rasse in zwei andere Retriever-Rassen.
Minimaländerung
Für uns ist es wichtig, dass unsere VKEDs mehrere Kriterien erfüllen.
Erstens sollte die Veränderung zum Originalbild minimal sein. Diffusionsmodelle sind sehr gut darin, Bilder für eine vorgegebene Klasse wie „Zebra“ zu erstellen. Für unser Ziel, Klassifikatorentscheidungen erklären zu wollen, ist es jedoch nicht hilfreich, wenn das neue Bild nicht unserem Ausgangsbild ähnlich ist, sondern stattdessen ein ganz anderes Zebra auf einem anderen Hintergrund zeigt. Um sicherzustellen, dass der Klassifikator das gewünschte Objekt anvisiert, verändert unsere Erklärungsmethode nur die wichtigsten Teile des Bildes: In diesem Fall wird das Fell des Pferdes in ein schwarz-weißes Zebramuster umgewandelt, während der Hintergrund unverändert bleibt.

Realismus
Darüber hinaus sollten die Bilder realistisch aussehen. Es wäre z. B. sehr einfach, einen Klassifikator, der Katzen von Hunden unterscheiden kann, dazu zu bringen, „Katze“ vorherzusagen, indem man mehrere „Katzenohren“ in das Bild einfügt. Das wäre jedoch kein realistisches Bild. Eine realistischere VKED hingegen würde vielleicht die Ohren auf einem Hundebild in Katzenohren umwandeln und prototypische Fellmuster von Katzen einfügen.
Deshalb stützen sich unsere VKEDs auf Diffusionsmodelle, um realistischere Bilder zu erzeugen. Denn Diffusionsmodelle haben aufgrund ihrer Analyse von Millionen verschiedener Bilder gelernt, „wie echte Bilder aussehen“.
Nun, da wir eine Vorstellung davon haben, wie VKEDs funktionieren, was können wir praktisch damit anstellen?
Fehlerbeseitigung bei Klassifikatoren
Eine Anwendungsmöglichkeit von VKEDs besteht darin, eine vom Klassifikator gelernte Verzerrung zu entdecken. In Abbildung 3 zeigen wir ein Beispiel, bei dem ein Bildklassifikator für die Erkennung der Klasse „Biene“ mit vielen Bildern trainiert wurde, die im Hintergrund Blumen zeigen (Beispiele rechts). Der Klassifikator erzeugt nun mittels VKED für die Klasse „Biene“ Bilder, die zwar Blumen enthalten, aber keine Bienen. Dies verdeutlicht, dass der Klassifikator sich angelernt hat, diese Klasse auch dann vorherzusagen, wenn keine Bienen und nur Blumen im Bild vorhanden sind.

Abbildung 3. VKED (Mitte) des Originalbildes (links) für einen ImageNet-Klassifikator mit dem falschen Merkmal „Blume“ für die Zielklasse „Biene“ (d. h. Bilder, die nur Blumen enthalten, haben bereits eine hohe Wahrscheinlichkeit, als Biene klassifiziert zu werden). Rechts ist ein Beispiel aus dem ImageNet-Trainingsdatensatz zu sehen.
VKEDs für medizinische Klassifikatoren
Darüber hinaus können solche Erklärungen auch für medizinische Anwendungen benutzt werden, z. B. für die Klassifizierung der diabetischen Retinopathie anhand von Netzhautbildern. Für diese Aufgabe haben wir in einem kürzlich erschienenen Artikel bereits VKEs für jegliche Bildklassifikatoren erstellt. Um jedoch die Realitätsnähe zu erhöhen, arbeiten wir an der Anwendung von VKEDs für diese Klassifikatoren (s. Abb. 4). Hier generieren wir für ein Netzhautbild mit diabetischer Retinopathie (DR), für das ein Klassifikator ebenfalls eine DR vorhersagt, eine VKED für die Zielklasse „gesund“, welche die wichtigsten Krankheitsmerkmale entfernt (z. B. werden rote Blutungen und gelbe harte Exsudate entfernt, und die Arterien bleiben erhalten). Solche VKEDs können Ärzten, die mit Deep-Learning-Bildklassifikatoren arbeiten, dabei helfen, Entscheidungen zu treffen. Denn auf diese Weise können sie besser erkennen, warum ein Modell eine bestimmte Entscheidung getroffen hat.
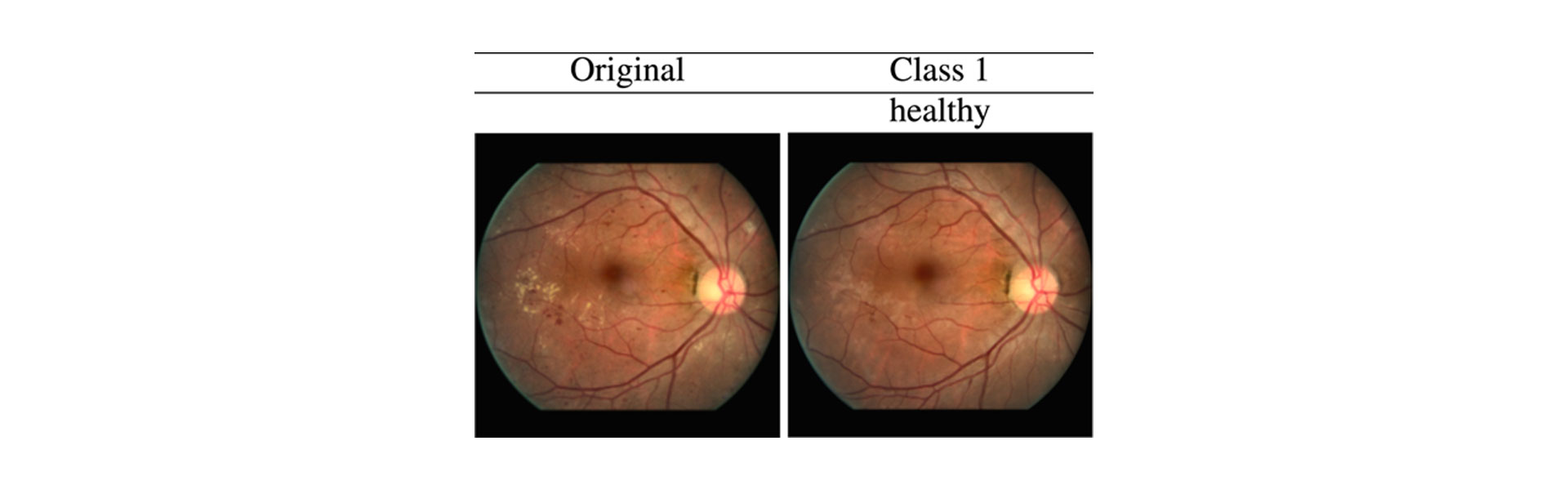
Abbildung 4. VKEDs für einen Klassifikator, der ein Bild der erkrankten Klasse „DR“ in eins der „gesunden“ Klasse umändert, indem es die wichtigsten Krankheitsmarker entfernt.
Ein Blick in die Blackbox
Die Forderung nach Transparenz richtet sich nicht nur auf Entscheidungsfindungen, die den Menschen betreffen, sondern stellt ein dringendes Anliegen bei allen Anwendungen des maschinellen Lernens dar. Denn der Mensch möchte ebenso verstehen wie auch kontrollieren, ob der trainierte Algorithmus die Konzepte der zugrundeliegenden Klassen richtig erfasst hat oder ob er nur deshalb gute Vorhersagen macht, weil er irreführende Merkmale aufgreift, die auf Artefakte im Datensatz beruhen können. Auch wenn noch viele Fragen offen sind und Manches noch im Verborgenen liegt, kann man mithilfe von VKEDs einem Teil des Entscheidungsprozesses auf die Spur kommen, da diese nur kleine, aber realistische Änderungen an den Bildern vornehmen, die durch einen Diffusionsprozess entstehen. Auf diese Weise können wir die Entscheidungen von Modellen genauer nachverfolgen und gehen damit einen Schritt näher in Richtung Transparenz, indem wir die „Blackbox“ der Modelle öffnen.
Originalpublikation:
Maximilian Augustin, Valentyn Boreiko, Francesco Croce, Matthias Hein: Diffusion Visual Counterfactual Explanations. Advances in Neural Information Processing Systems (NeurIPS), 2022
Paper: https://arxiv.org/abs/2210.11841
Titelillustration: Franz-Georg Stämmele
Übersetzung ins Deutsche: Aikaterini Filippidou
Maschinelles Lernen verbessert superauflösende Mikroskopie

Wie man neuronale Netze mit Unsicherheiten ausstattet

Kommentare