In seiner ikonischen Fantasieerzählung “Die Bibliothek von Babel“ (1941) beschreibt Jorge Luis Borges eine Bücherei, die alle Bücher umfasst, die je geschrieben wurden. Trotz dieser ungeheuren Wissensfülle sind die meisten Bücher völlig nutzlos. Das treibt die nach Orientierung suchenden Bibliothekare zur Verzweiflung. Wer heute versucht, übers Internet eine Fremdsprache zu lernen oder sich im Dschungel der sonstigen Online-Bildungsangebote zurechtzufinden, kann ein ähnliches Schicksal erleiden. Die meisten Lern-Apps passen sich nicht den individuellen Fähigkeiten des Nutzers an wie es eine Lehrerin tun würde, sondern muten ihm schon mal zu, sinnlose Phrasen endlos zu wiederholen. Beim Lernen mit Videos oder Blog-Posts ist es oft unmöglich, die Menge an dargebotenen Informationen schlüssig für sich zu gliedern. Da wäre es doch praktisch, wenn künstliche Intelligenz hier die Rolle eines Bibliothekars oder einer Lehrkraft einnehmen und die Lernenden, angepasst an deren Fähigkeiten, zu den für sie hilfreichsten Inhalten führen könnte.
In unserem jüngsten Projekt, das wir bei der internationalen Konferenz ICLR in einem Spotlight-Vortrag vorgestellt haben, haben wir uns dieser Herausforderung gestellt und uns mit einem neuen Ansatz des maschinellen Lernens das Problem der “strukturierten Wissensverfolgung” (Englisch: structured knowledge tracing) vorgeknöpft. Herausgekommen ist ein System, das den Wissensstand des Lernenden in Echtzeit verfolgt und es uns so ermöglicht, treffsicher vorherzusagen, wie gut er bei einer beliebig vorgebbaren Folgeaufgabe abschneiden wird. In Zukunft kann dies genutzt werden, um Lernenden maßgeschneiderte Empfehlungen für ihre nächsten Lernschritte zu geben. Unser Modell haben wir “PSI-KT” getauft, was ausgeschrieben heißt: “Prädiktive, Skalierbare und Interpretierbare Wissensverfolgung“ (Englisch: Predictive, Scalable, and Interpretable Knowledge Tracing”). Diese drei Elemente bilden zusammen das Fundament für das anvisierte Tutoring-System. Wie funktioniert PSI-KT also?
Wissensverfolgung lässt den Lernverlauf vorhersagen
Um ihre Schülerinnen und Schüler an ihre Lernziele heranzuführen, müssen Lehrkräfte geeignete Lernaktivitäten vorgeben. Dazu müssen sie jederzeit über den aktuellen Wissensstand der Lernenden im Bilde sein — eine Aufgabe, die man als Wissensverfolgung bezeichnet.
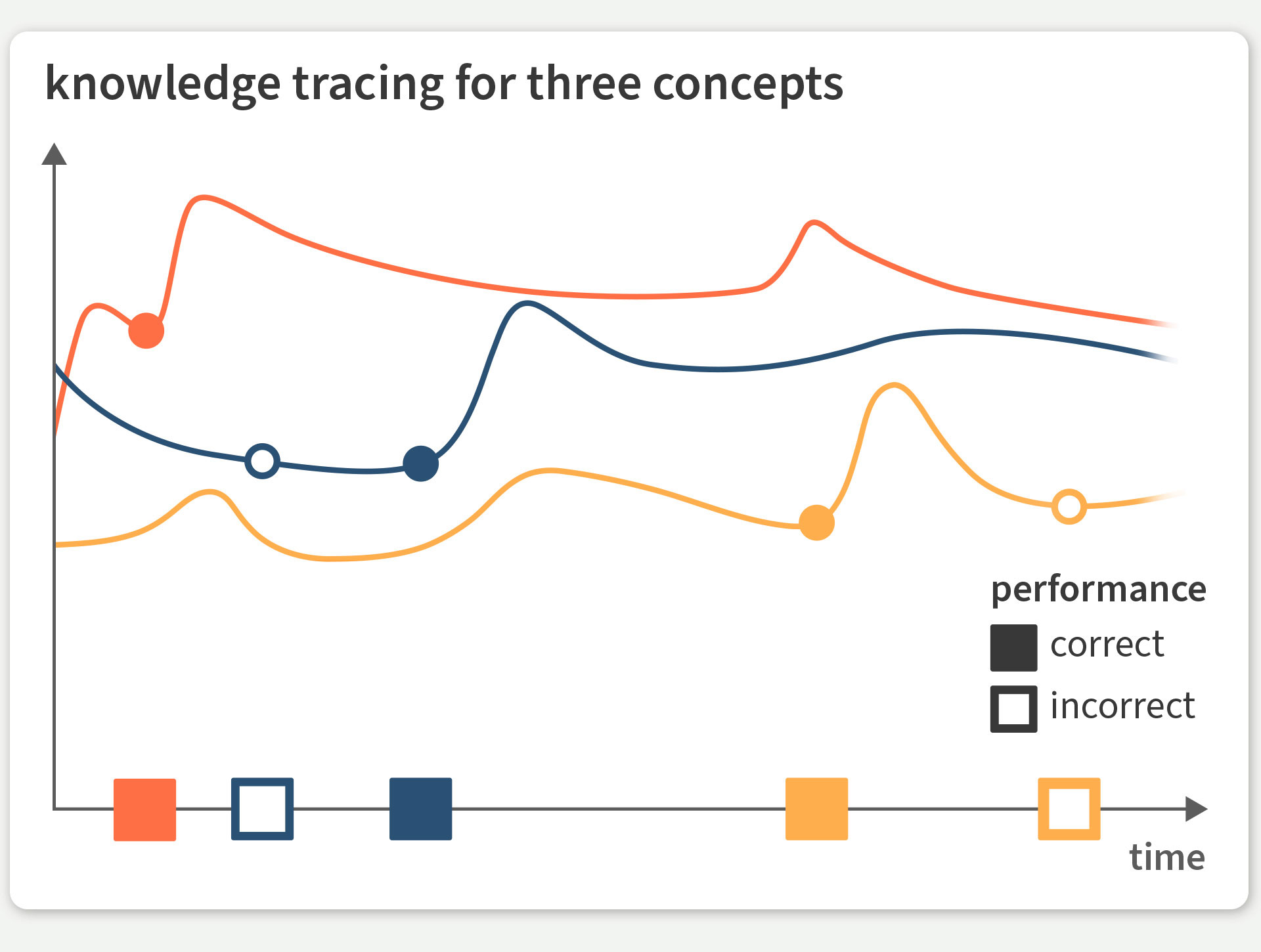
Abb. 1: Auf der Grundlage von Lernerfolgen (ausgefüllte Kästchen) und -misserfolgen (leere Kästchen), die der Lernende nach Beschäftigung mit verschiedenen Sachverhalten (gekennzeichnet durch die unterschiedlichen Farben) verzeichnet, schätzt das Wissensverfolgungssystem ab, wie sich sein Wissen im Lauf der Zeit entwickelt, und sagt künftige Leistungen vorher.
Abhängigkeiten zwischen verschiedenen Lerninhalten erkennen
Eine der wichtigsten Eigenschaften unseres Modells ist, dass es Wissensstrukturen erfasst, also wie Wissen aufeinander aufbaut. In der Lernpsychologie spricht man von der Zone proximaler Entwicklung, wenn Fähigkeiten und Wissen bereits in Sichtweite sind, die Lernenden aber noch Unterstützung benötigen, um sie zu erreichen. Während eine gute menschliche Lehrkraft ihren Schülerinnen und Schülern hier spielend leicht die erforderliche Hilfestellung geben kann, fehlt es Online-Lernprogrammen oft am Verständnis dafür, wie Sachverhalte miteinander zusammenhängen. Um eine präzise und nutzbringende Wissensverfolgung zu ermöglichen, müssen wir daher die Strukturen kennenlernen, die erklären, wie eine bestimmte Kompetenz den Erwerb einer anderen fördert. Das Addieren von zwei Zahlen ist zum Beispiel eine gute Vorbereitung zum Verständnis der Multiplikation. So haben wir alle in der Grundschule das Multiplizieren gelernt. Wie kann man nun aber einer KI beibringen, für ein beliebiges Wissensgebiet in der realen Welt die Hierarchien des Lernens zu erfassen, die für den Kompetenzerwerb erforderlich sind?
Bei PSI-KT richten wir uns nach Leistungsdaten: Wenn die Schülerinnen und Schüler, die zuerst das Addieren und danach das Multiplizieren üben, erwartungsgemäß schneller lernen als solche, die in der umgekehrten Reihenfolge vorgehen, dann betrachten wir die Addition als Voraussetzung für die Multiplikation. Hier orientiert sich unsere Methode nur danach, welchen Einfluss die Reihenfolge der vermittelten Lerninnhalte auf den empirischen Lernerfolg hat. Wir benötigen also keine manuell erstellten Angaben darüber, welche Lerninhalte auf welchen anderen Lerninhalten aufbauen. Diese Angaben sind in öffentlich verfügbaren Datensätzen nämlich selten vorhanden. Außerdem lässt sich so die Privatsphäre besser schützen, da keine expliziten Lernerfolge aufgezeichnet werden müssen, sondern nur deren Rückschlüsse auf Abhängigkeiten zwischen Lerninhalten.
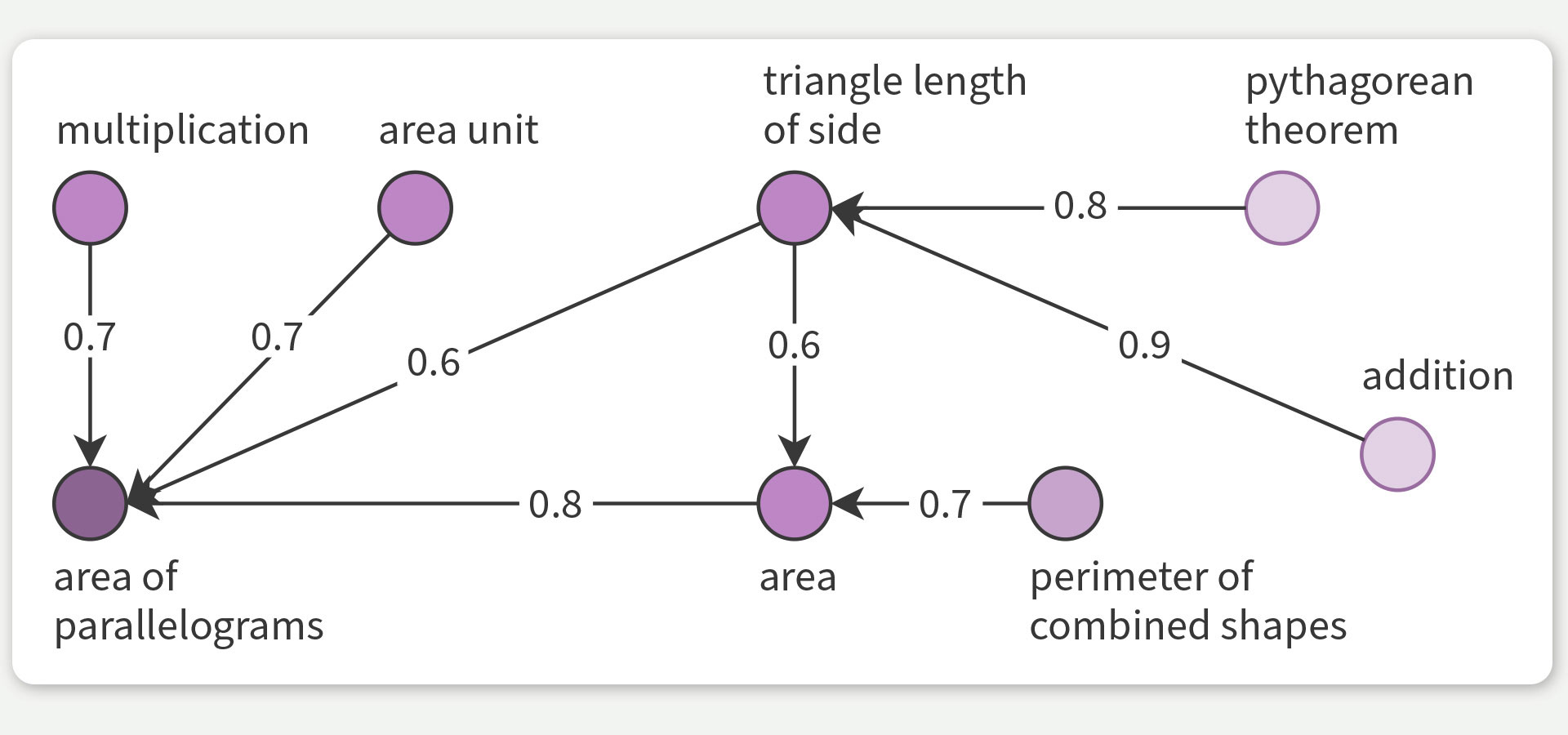
Abb. 2: Beim Knowledge Mapping wird abgeschätzt, in welchem Maß der Erwerb einer Kompetenz den Erwerb einer anderen fördert. Für den Erwerb der Fähigkeit, den Flächeninhalt eines Parallelogramms zu berechnen (unten links), schätzt PSI-KT also, in welchem Maße bestimmte vorbestehende Kompetenzen notwendig sind und ordnet diesen entsprechende Zahlenwerte zwischen 0 und 1 zu. PSI-KT verwendet ausschließlich Leistungsdaten – die Bezeichnungen der erlernten Inhalte (Multiplikation, Flächenmaß usw.) dienen hier nur zur Illustration.
Mit der Sammlung von immer mehr Leistungsdaten von Lernenden verbessert sich im Lauf der Zeit unsere Knowledge Map so weit, dass wir Lernerfolge bei künftigen Aufgaben vorhersagen können. Das funktioniert auch bei neuen Teilnehmerinnen und Teilnehmern, die noch gar nicht mit dem System interagiert haben. Mit dieser Aussicht eröffnet sich für PSI-KT ein breites Anwendungsfeld in jeder beliebigen Fachdisziplin, und zwar selbst dann, wenn eine von Fachleuten erstellte Knowledge Map noch gar nicht zur Verfügung steht.
Mit weiteren Daten kann sich das Modell kontinuierlich verbessern
Ein Aspekt, der KI-Entwicklerinnen und -Entwicklern im Bildungsbereich zu schaffen macht, sind die großen Datenmengen, die Deep-Learning-Systeme zum Training benötigen. Hinzu kommt, dass die Modelle bei der Aufnahme weiterer Daten von Neuem trainiert werden müssen, was sowohl den Geldbeutel als auch die Umwelt strapaziert.
Anders als die meisten Modelle des maschinellen Lernens, kann PSI-KT allerdings seine Parameter aktualisieren, ohne mit dem Training von Neuem beginnen zu müssen. Es kann auch allgemeine Trends im Lernverhalten erfassen, die in der Gesamtpopulation aller Lernenden auftreten. Damit können wir auch bei neu hinzukommenden Teilnehmerinnen und Teilnehmern, mit denen unser Modell noch gar nicht die Gelegenheit hatte zu interagieren, gute Prognosen machen.
Personalisierung, die sich in Worten beschreiben lässt
Ein einzigartiger Vorteil unseres Modells ist schließlich seine Interpretierbarkeit. An Deep-Learning-Systemen wird oft kritisiert, dass man sich ihre große Vorhersagekraft mit mangelnder Interpretierbarkeit erkauft. Viele andere Deep-Learning-Modelle zur Wissensverfolgung stellen das Lernverhalten der Nutzerinnen und Nutzer in Form von Zahlenkolonnen dar, aus denen sich für uns Menschen kaum ein Sinn herauslesen lässt.
PSI-KT wurde dagegen von Anfang an darauf ausgelegt, Merkmale des Lernverhaltens zu erfassen, die sich mit psychologischen Begriffen beschreiben lassen – zum Beispiel, wie schnell ein Lernender Inhalte vergisst oder wie gut er Wissen aus einem Bereich auf einen anderen übertragen kann. Anhand von Daten aus Bildungsplattformen zeigen wir, dass diese kleine Anzahl von Merkmalen die beobachteten Lernmuster durchweg zuverlässig vorhersagt. Damit wird es möglich, aussagekräftiges Feedback über den Lernprozess zu geben, das sowohl Lehrkräften als auch dem Lernenden selbst zugutekommen kann.
Fazit
In PSI-KT haben wir Erkenntnisse über menschliches Lernverhalten und maschinelles Lernen zusammengeführt und so die Grundlage für eine neue Generation von Tutoring-Systemen auf KI-Basis geschaffen. Wir hoffen, dass solche Systeme Lernenden in Zukunft helfen können, im Dschungel der Online-Lernangebote besser zurechtzukommen.
Originalpublikation: Zhou, H., Bamler, R., Wu, C. M., & Tejero-Cantero, A. (2024). Predictive, scalable and interpretable knowledge tracing on structured domains. The Twelfth International Conference on Learning Representations. https://doi.org/10.48550/arXiv.2403.13179
Titelillustration: Franz-Georg Stämmele
Übersetzung ins Deutsche: Conrad Heckmann

20 Millionen Papers gleichzeitig durchforsten und neues Wissen freilegen

Kommentare